Deep research agents have gotten significantly better. Tools like Perplexity, OpenAI Deep Research, and Gemini can search, synthesize, and return structured answers across dozens of sources. The quality of the output has improved fast.
What these tools don’t make visible is the process. When they stop searching, you don’t know if the work is done or the budget ran out. When two sources conflict, you don’t know if that got noticed or smoothed over. The output looks the same either way.
The core idea was to build a research agent where those questions have explicit answers — not by retraining a model, but by designing the right structure around it: an explicit evidence state, step-level reward signals, and a planner that uses those signals to decide what to do next. This is what I built, how I designed it, and what it taught me.
The design challenge: measuring research quality without retraining
Most research pipelines evaluate quality at the end — how good does the final report look? That’s a reasonable starting point, but it leaves a lot invisible. You can’t tell from the report alone whether the search was principled, whether the agent explored the right sub-questions, or whether it stopped because the work was done or because it hit a time limit.
The challenge I wanted to tackle: how do you build visibility into the research process itself — without retraining the underlying model?
The field has a well-developed answer to this for chain-of-thought reasoning: Process Reward Models — models that score the quality of each intermediate reasoning step rather than just the final output. Each step either advances the goal or it doesn’t.
The question I started with: what does a step-level reward signal look like for a research agent?
The approach I took: evidence state improvement is the reward. The evidence state is a structured record of what the system has found, confirmed, disputed, and still needs to explore. Improving it means adding a new claim from a new source, surfacing a contradiction, covering an unexplored sub-question. If a step doesn’t change the evidence state, it contributed nothing, regardless of how good the retrieved text looks.
The architecture
The high-level flow:
Query
-> Decomposer
-> Planner (baseline or guided)
-> Retriever (search + rerank + domain filtering)
-> Claim Extractor (+ claim filter)
-> Conflict Engine
-> Evidence Store update
-> Evaluator (step signal)
-> Stop criteria check
-> Report + Traces (run_trace captures the full step sequence for analysis)
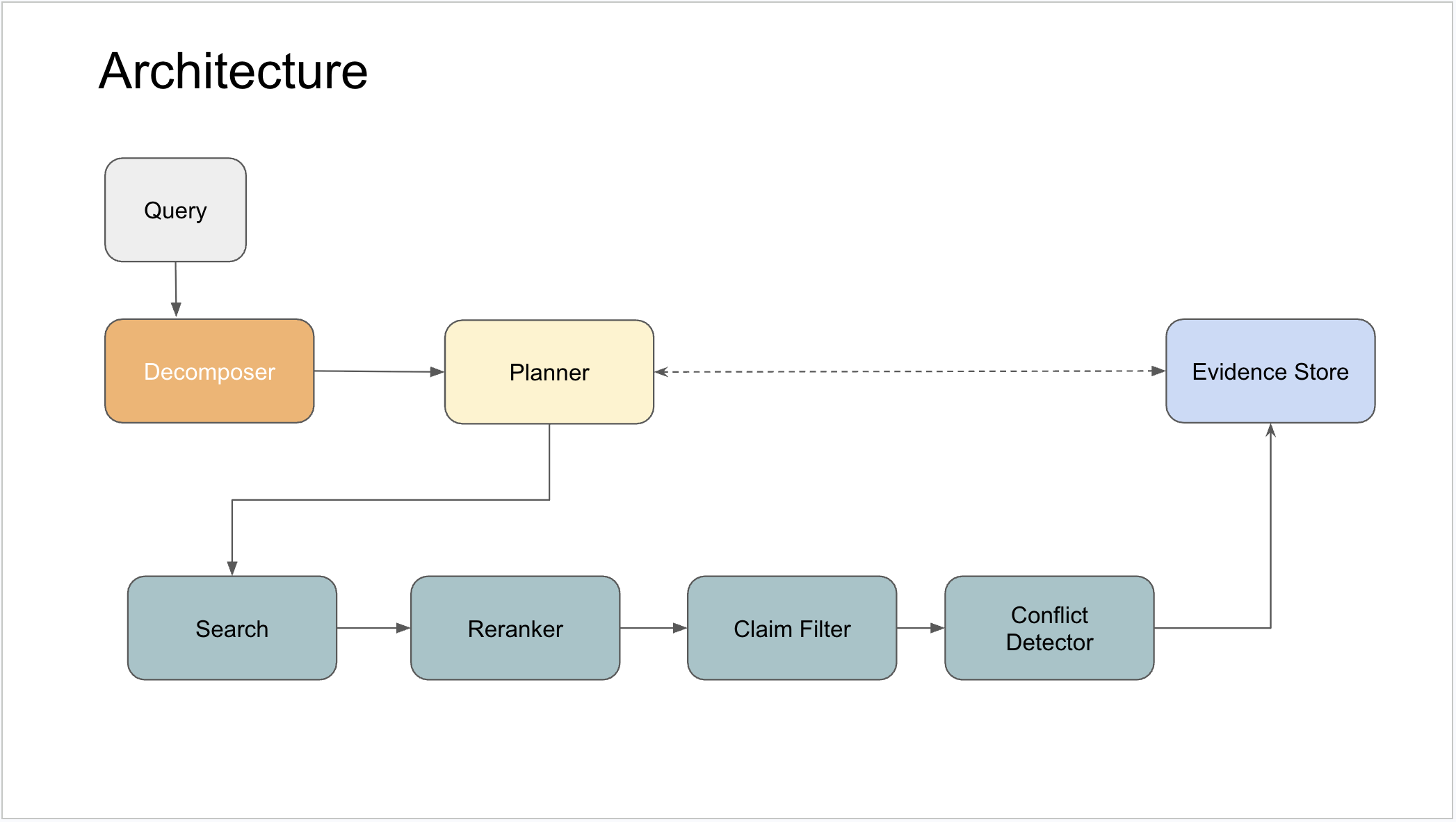
The architecture is a single research loop — one evidence state that every component reads from and writes to. The planner decides what to search next, the retrieval pipeline extracts and filters claims, and the evidence store tracks what’s confirmed, what’s disputed, and what’s still missing. The report is generated from whatever is in that record at the end.
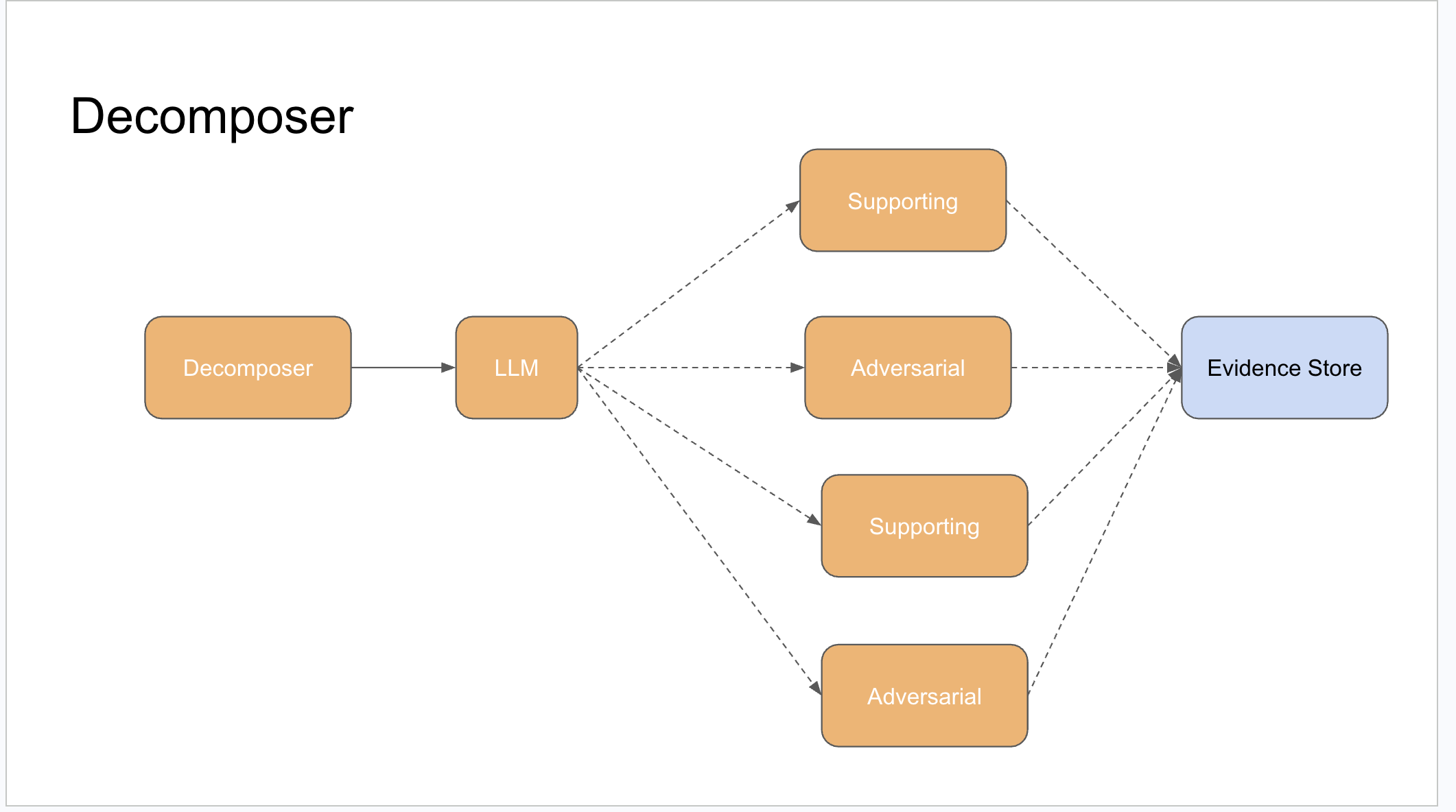
Decomposition: supporting and adversarial sub-questions
The first thing the system does is decompose the query into sub-questions. But not just supporting ones — it generates adversarial sub-questions too.
Supporting sub-questions search for evidence in favor of a claim. Adversarial sub-questions explicitly search for counter-evidence, edge cases, and reasons a claim might not hold. This matters because most research agents stop when they find a confident answer. This one is designed to keep looking for reasons to doubt it.
Both types feed into the same evidence store. The planner tracks which sub-questions have been covered and which haven’t, and uses that coverage state to decide what to search next.
The retrieval pipeline
Each search action runs through a multi-stage retrieval pipeline before anything reaches the evidence store:
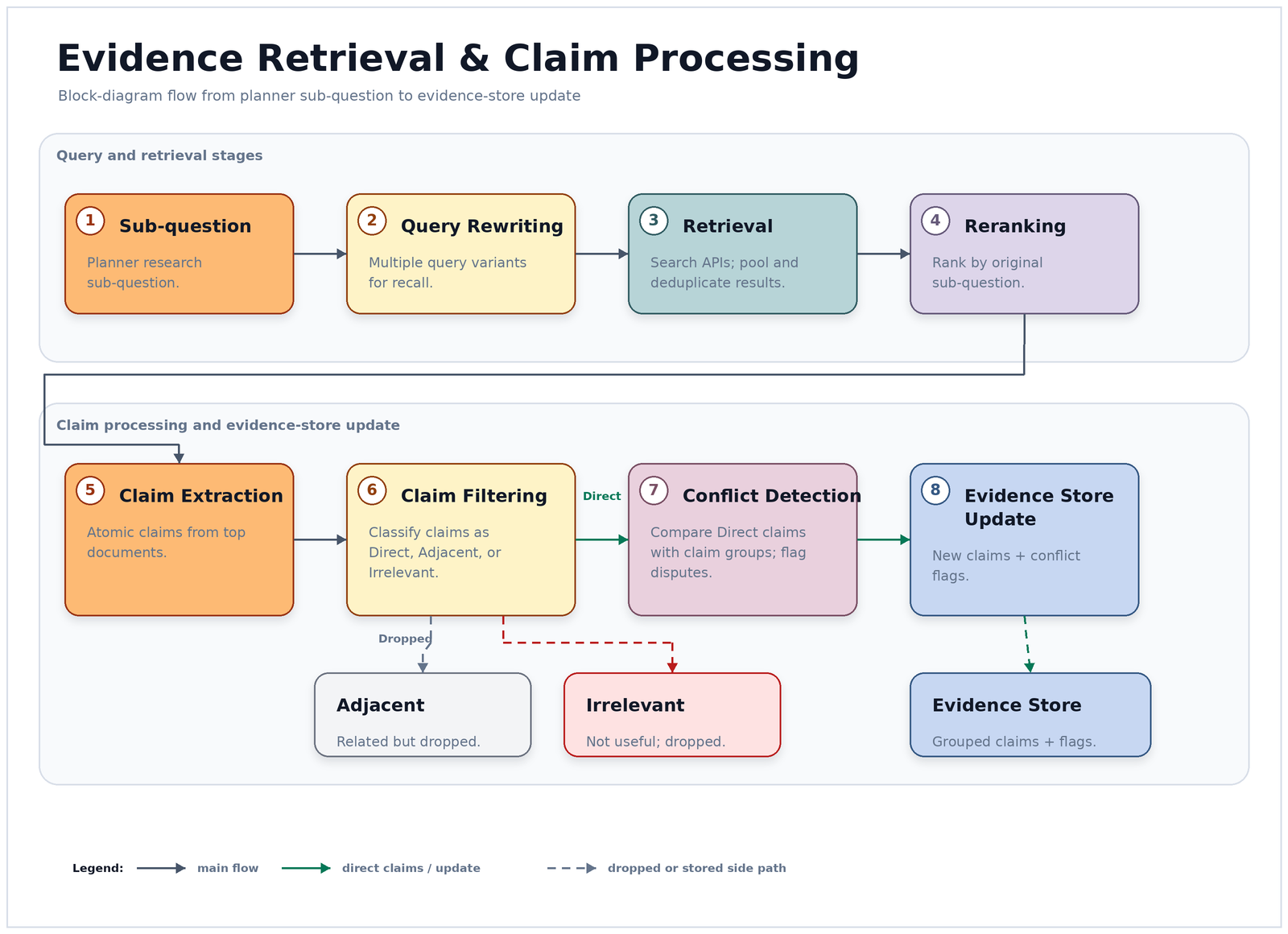
Query rewriting — the original sub-question gets rewritten into multiple variants to improve recall across different phrasings and keyword choices.
Retrieval — each variant gets sent to the search API. Results are pooled and deduplicated.
Reranking — retrieved documents are reranked by relevance to the original sub-question, not just the rewritten variant.
Claim extraction — an LLM extracts discrete claims from the top-ranked documents. Claims are atomic statements that can be evaluated individually — not paragraphs, not summaries.
Claim filtering — extracted claims are classified as direct (updates the main belief state), adjacent (related but not core), or irrelevant. Only direct claims update the evidence state.
Conflict detection — new claims are compared against existing claim groups. When a new claim contradicts an existing high-confidence claim group — a cluster of related claims about the same assertion — both get marked as disputed. The system doesn’t resolve the conflict — it surfaces it.
This pipeline runs inside every search step. The evidence store update only happens at the end of the full pipeline, once claims have been extracted, filtered, and checked for conflicts.
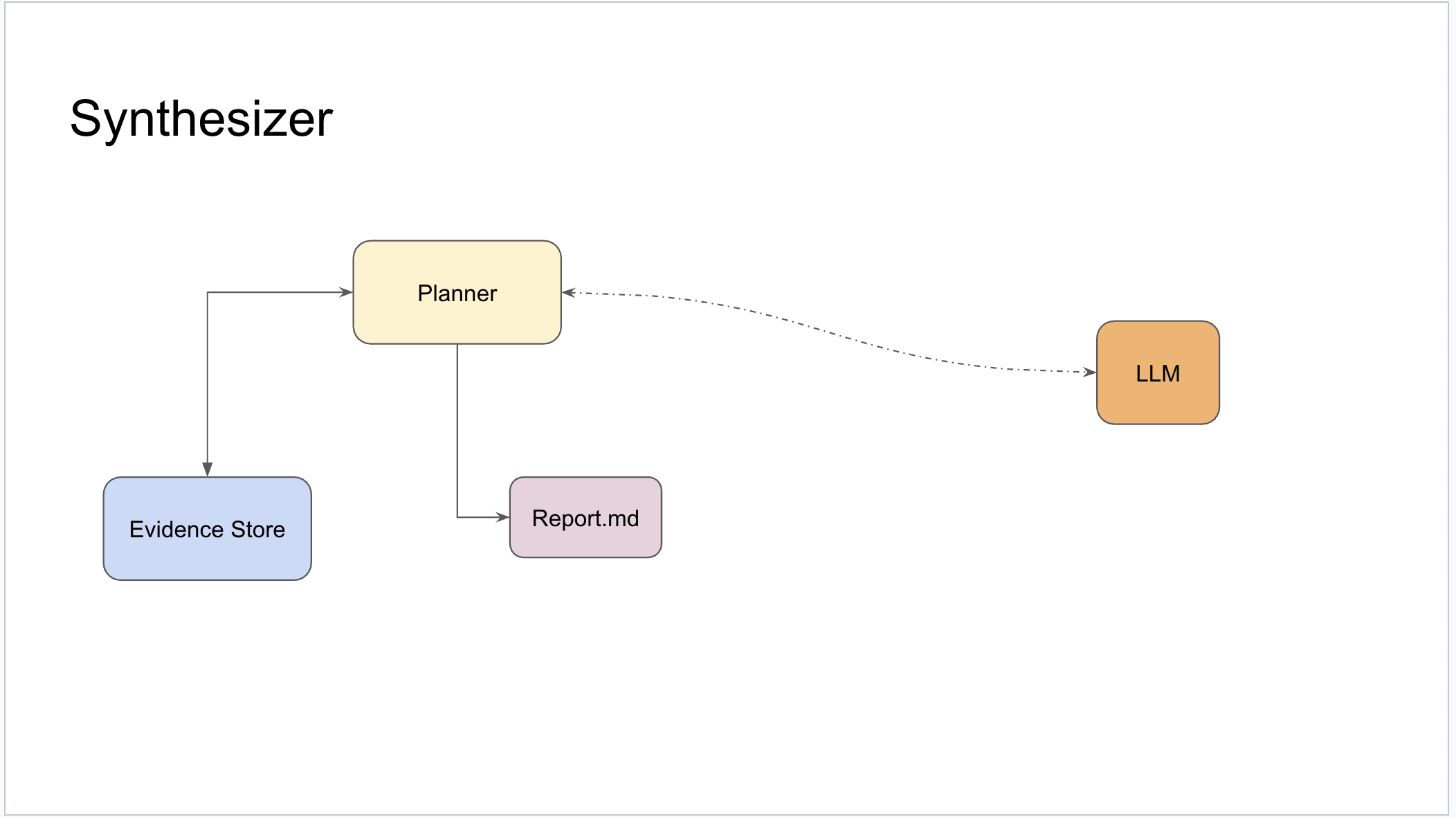
At the end of the research loop, the synthesizer reads from the evidence store directly to generate the final report — surfacing supported claims, flagging disputes, and disclosing gaps.
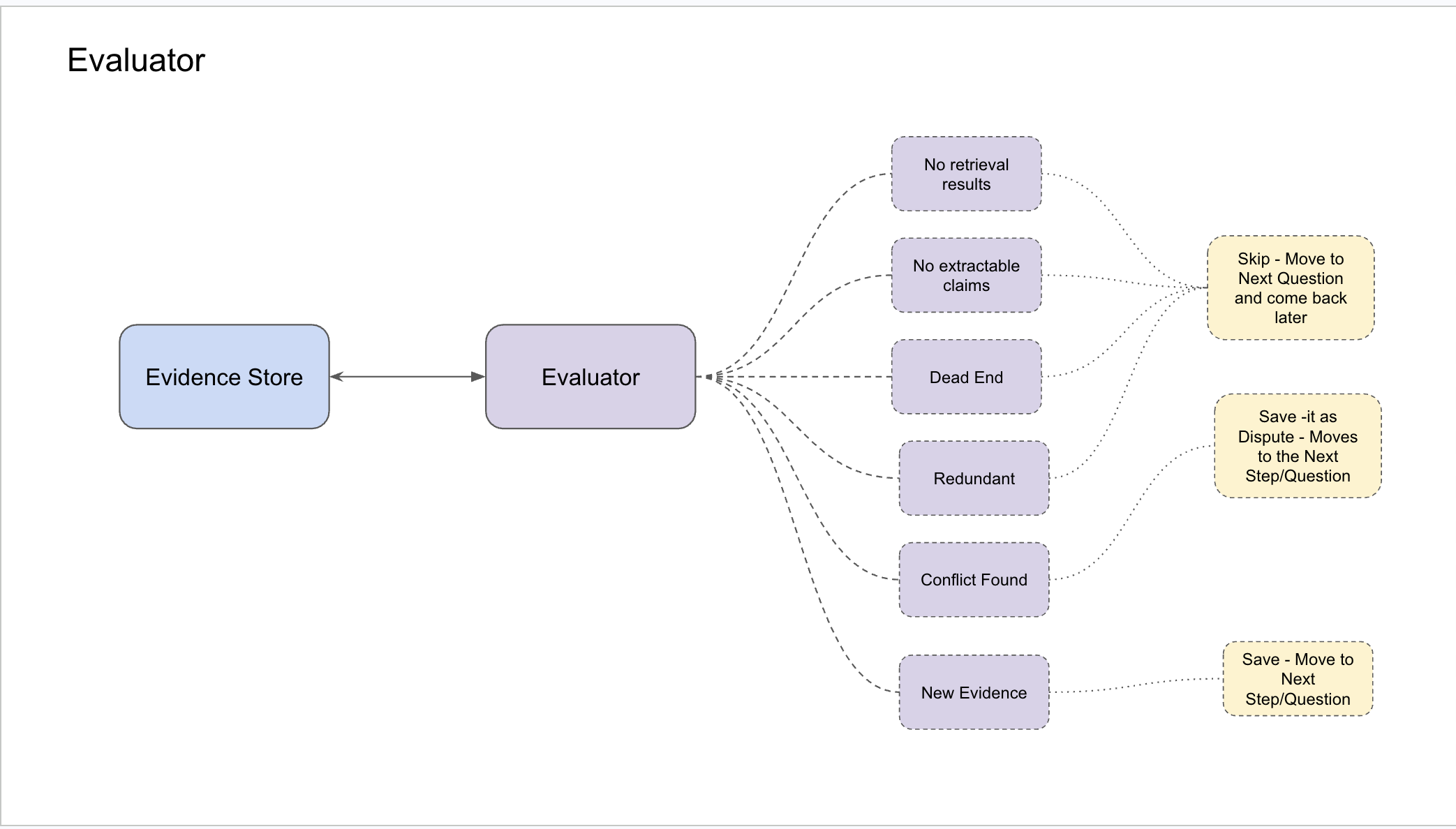
The evaluator: classifying each step
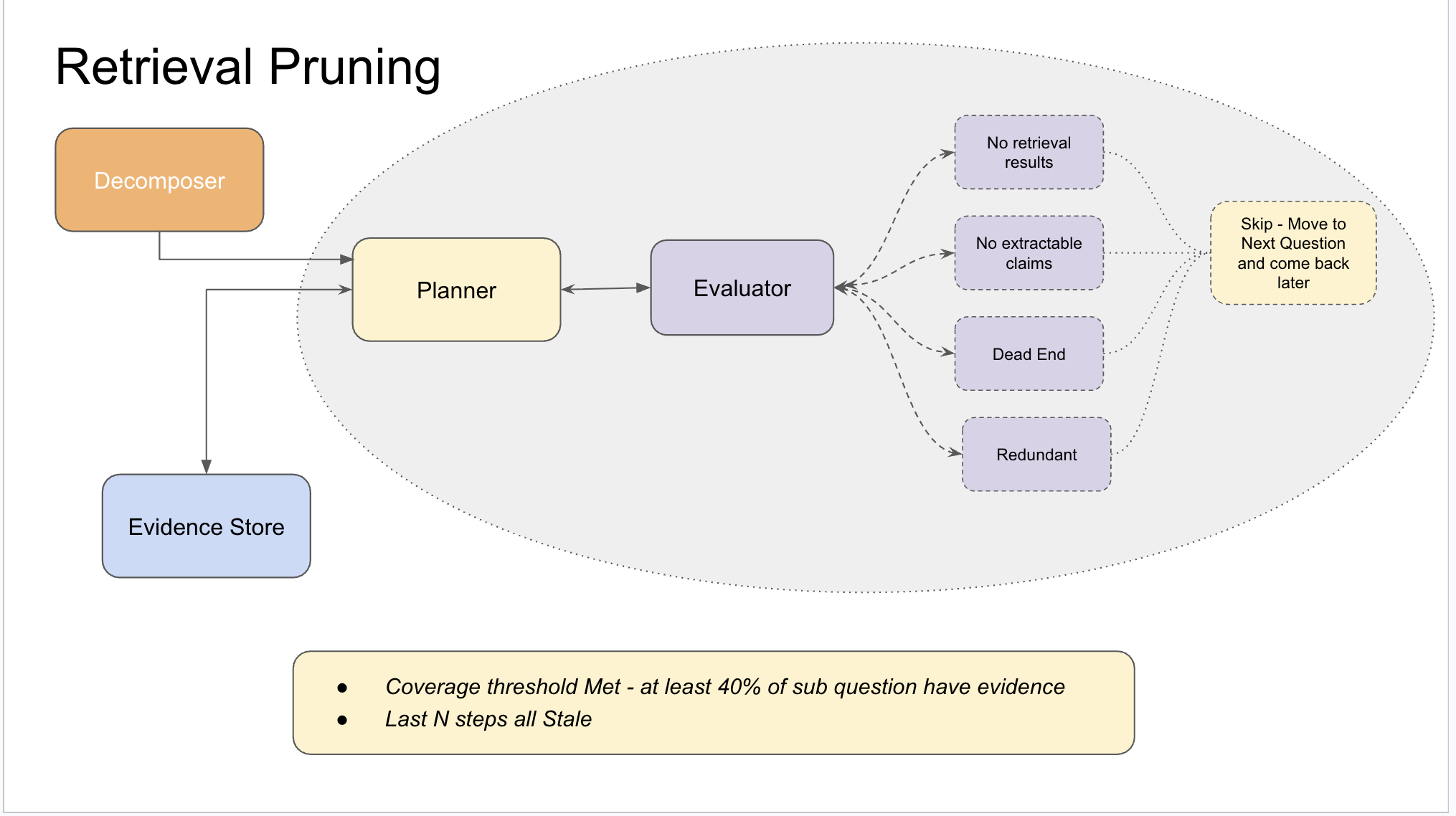
After every step, an evaluator classifies what happened to the evidence state:
| Signal | What it means |
|---|---|
NEW_EVIDENCE | New claim from a new source on an uncovered sub-question |
CONFLICT_FOUND | Surfaces a real contradiction in existing evidence |
REDUNDANT | Confirms existing evidence, nothing new |
DEAD_END | No extractable claims |
NO_RETRIEVAL_RESULTS | Search returned nothing |
The evaluator is deterministic — it checks observable conditions without an LLM call. Did new claims appear? Did a new source domain get added? Did a claim group flip to disputed?
This is a proxy for a trained process reward model. A trained PRM (Lightman et al., 2023) would score the full evidence state transition end-to-end. This one checks surface signals. But the signal structure is right, and that’s what matters for the planner to work.
CONFLICT_FOUND is treated as more valuable than REDUNDANT for a deliberate reason: surfacing a contradiction advances the evidence state more than confirming what you already know. Most research agents collapse conflicting evidence into a synthesis. This system marks it explicitly and discloses it in the report.
The guided planner
The planner reads evaluator signals and makes one of three decisions each step: search a new sub-question, issue a challenge (a targeted query designed to find contradicting evidence for a high-confidence claim), or stop.
Baseline mode cycles through sub-questions in fixed order and stops only when the step budget runs out. Guided mode reads the evidence state at every step — prioritizing uncovered angles, challenging high-confidence claims, and stopping when evidence is genuinely exhausted.
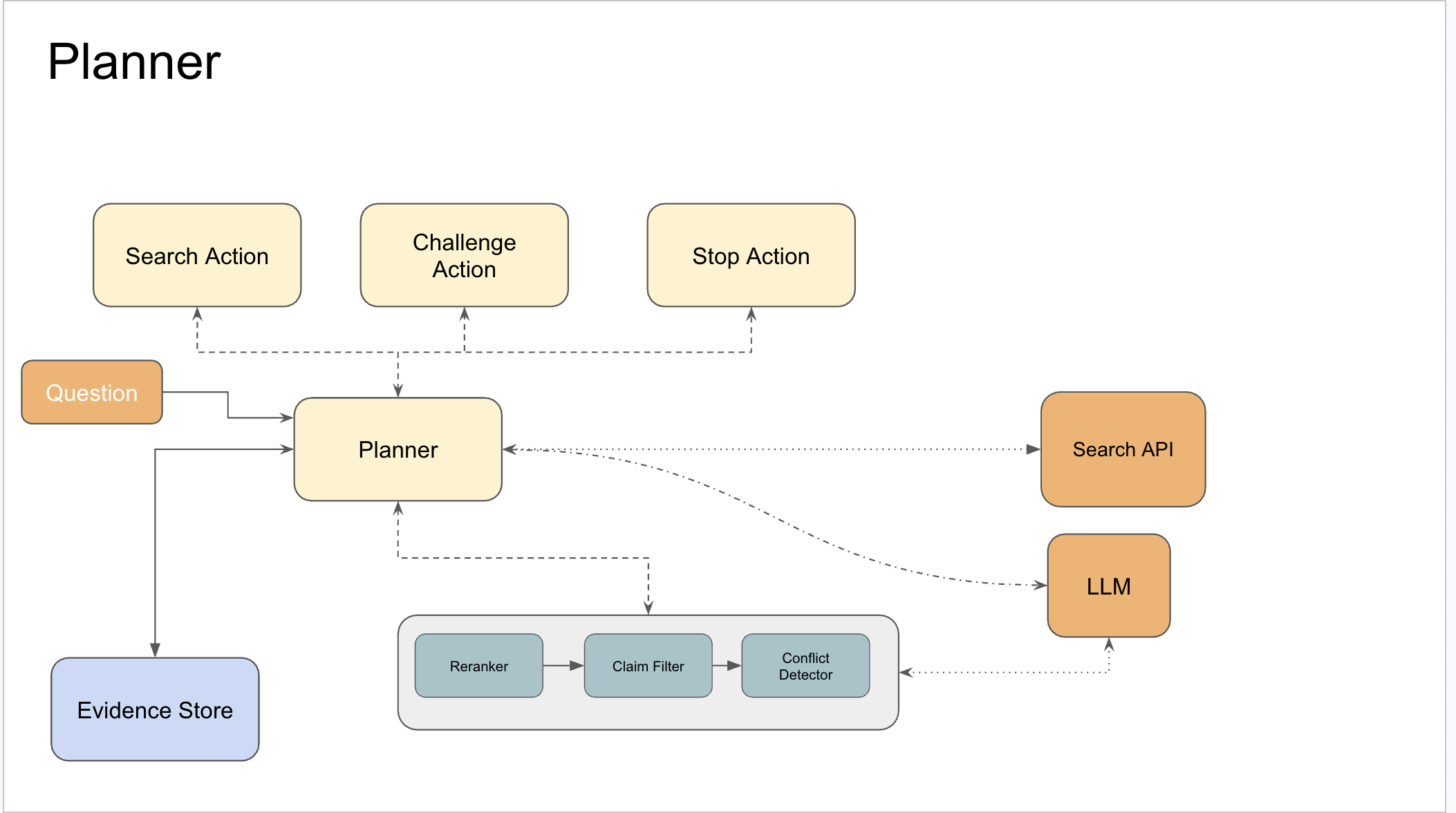
In guided mode, the planner follows three priorities:
1. Cover uncovered sub-questions first. Always explore unseen territory before reinvestigating what you already know. The planner maintains a priority queue over sub-questions weighted by coverage status and evidence density — how many claims have already been collected for that sub-question.
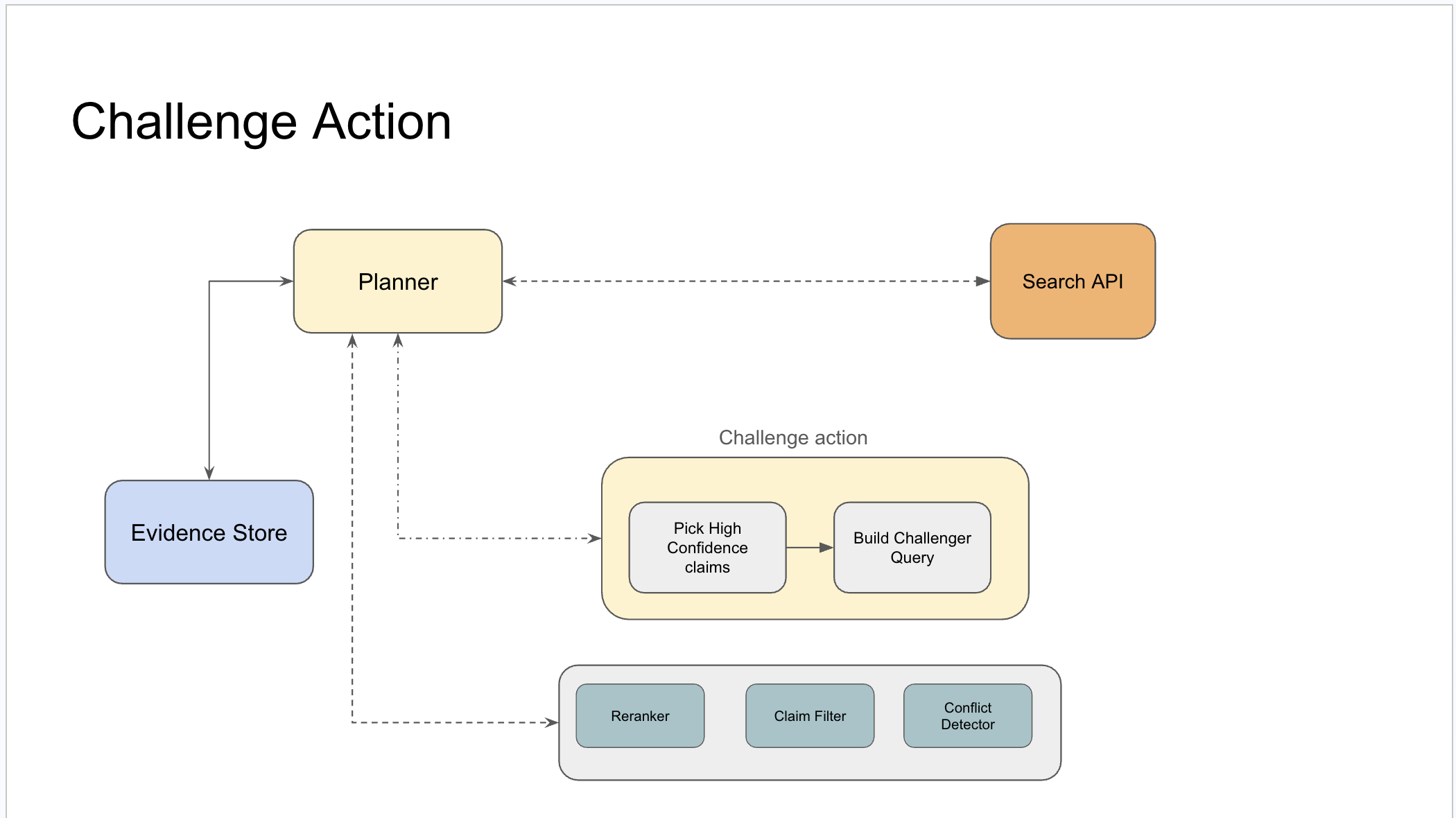
2. Challenge high-confidence claims. When a claim group reaches high confidence, the planner issues a Challenge Action — it builds a query specifically designed to find contradicting evidence. This is the adversarial behavior made operational.
3. Stop on diminishing returns. When the last 3 consecutive steps are all REDUNDANT or DEAD_END and all sub-questions have at least one evidence-backed claim, stop. This is principled stopping — the system stops because the research is done, not because the budget ran out.
4. Adapt to signals at every step. Baseline treats evaluator signals as noise — it cycles sub-questions in fixed order regardless of what the evaluator returns. Guided uses each signal as a decision input: DEAD_END escalates the query before moving on, REDUNDANT surfaces an uncovered sub-question, NEW_EVIDENCE on a high-confidence group may trigger a challenge. Failures get handled early; budget goes toward sub-questions that still have open territory.
What the ablation showed
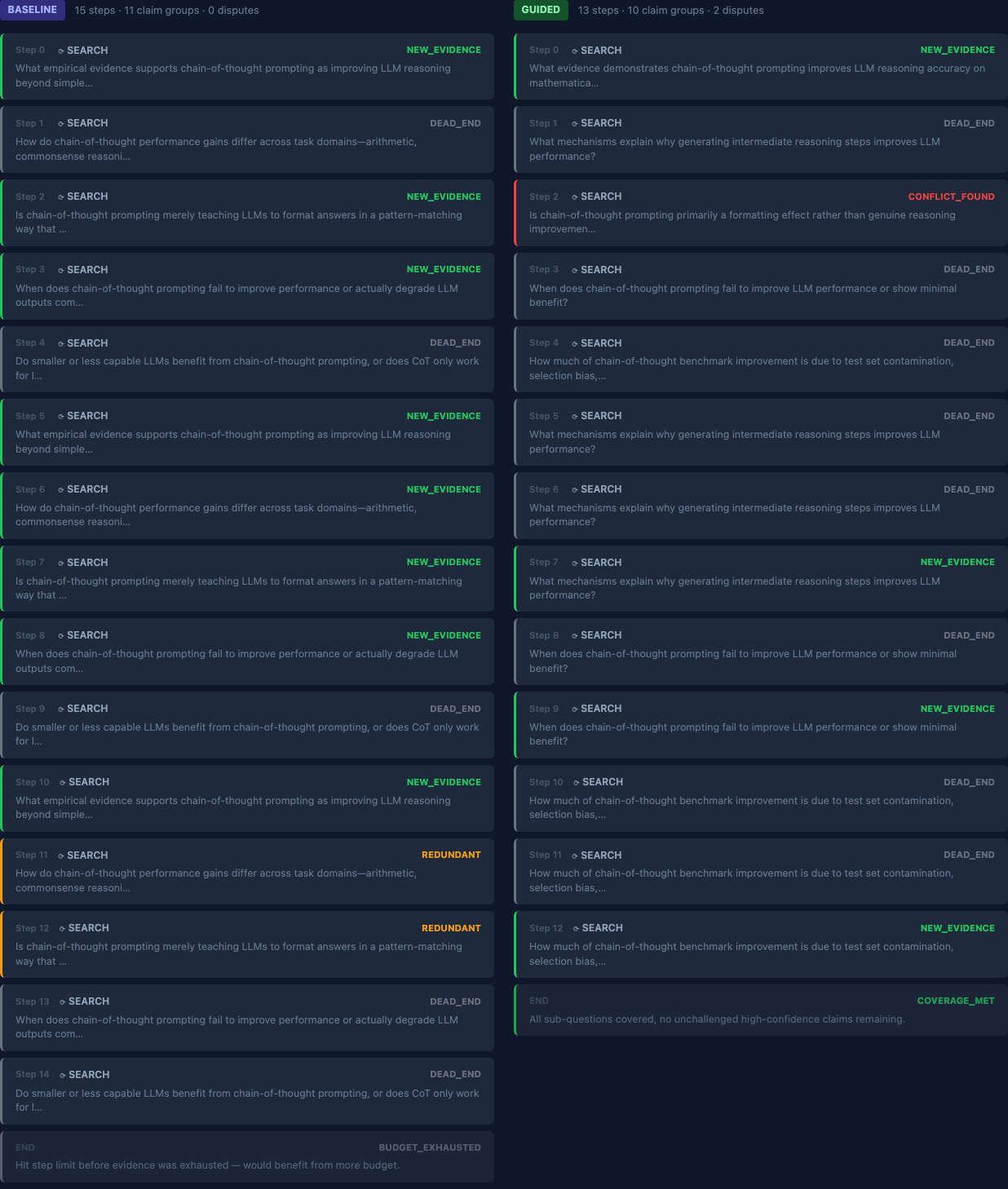
I ran two ablation pairs — same query, same model, baseline versus guided — and measured what changed. Two queries is a small sample and the metrics are self-defined proxies, not external ground truth. But the pattern is consistent across both runs, and the stopping behavior difference is visible in the step traces, not just the numbers.
Run 1 (chain-of-thought prompting):
Query: “Is chain-of-thought prompting an effective technique?”
| Metric | Baseline | Guided | Δ |
|---|---|---|---|
| Total steps | 15 | 6 | -9 |
| Termination | BUDGET_EXHAUSTED | COVERAGE_MET | — |
| Coverage completeness | 0.80 | 1.00 | +0.20 |
| Search efficiency | 0.53 | 0.83 | +0.30 |
| Summary grounding rate¹ | 0.67 | 1.00 | +0.33 |
| Disputes surfaced | 0 | 2 | +2 |
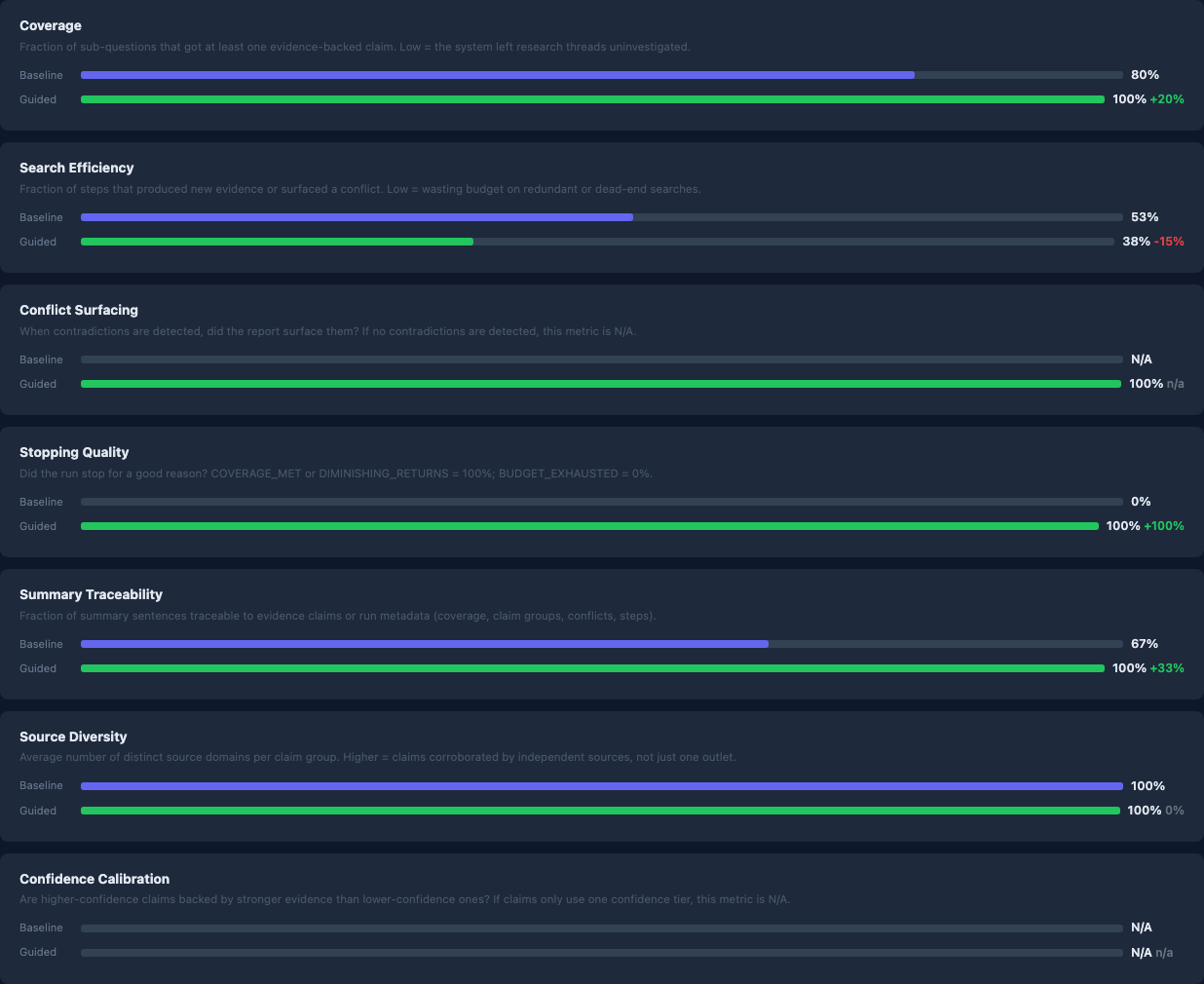
The key result: baseline exhausted its full budget and left one sub-question uncovered. Guided stopped at COVERAGE_MET with two conflicts surfaced. Baseline found zero.
¹ Summary grounding rate: fraction of summary sentences traceable to evidence claims or run metadata.

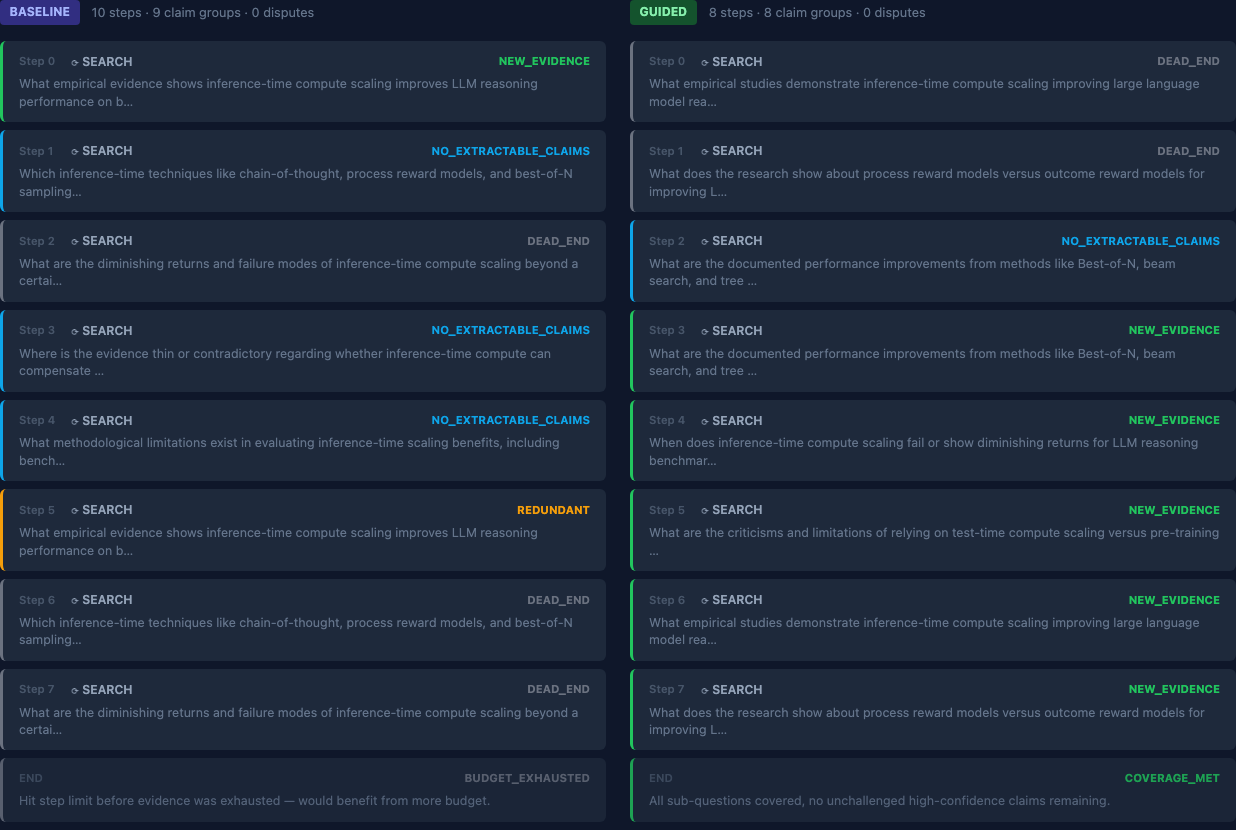
Run 2 (inference-time compute scaling):
Query: “What is the current state of inference-time compute scaling for LLM reasoning? Separate what has been empirically validated from what is still speculative, and identify where the evidence is too thin to draw conclusions.”
| Metric | Baseline | Guided | Δ |
|---|---|---|---|
| Total steps | 10 | 8 | -2 |
| Termination | BUDGET_EXHAUSTED | COVERAGE_MET | — |
| Sub-questions covered | 3/5 | 5/5 | +2 |
| Total LLM calls | 113 | 116 | +3 |
| Summary grounding rate¹ | 0.67 | 1.00 | +0.33 |
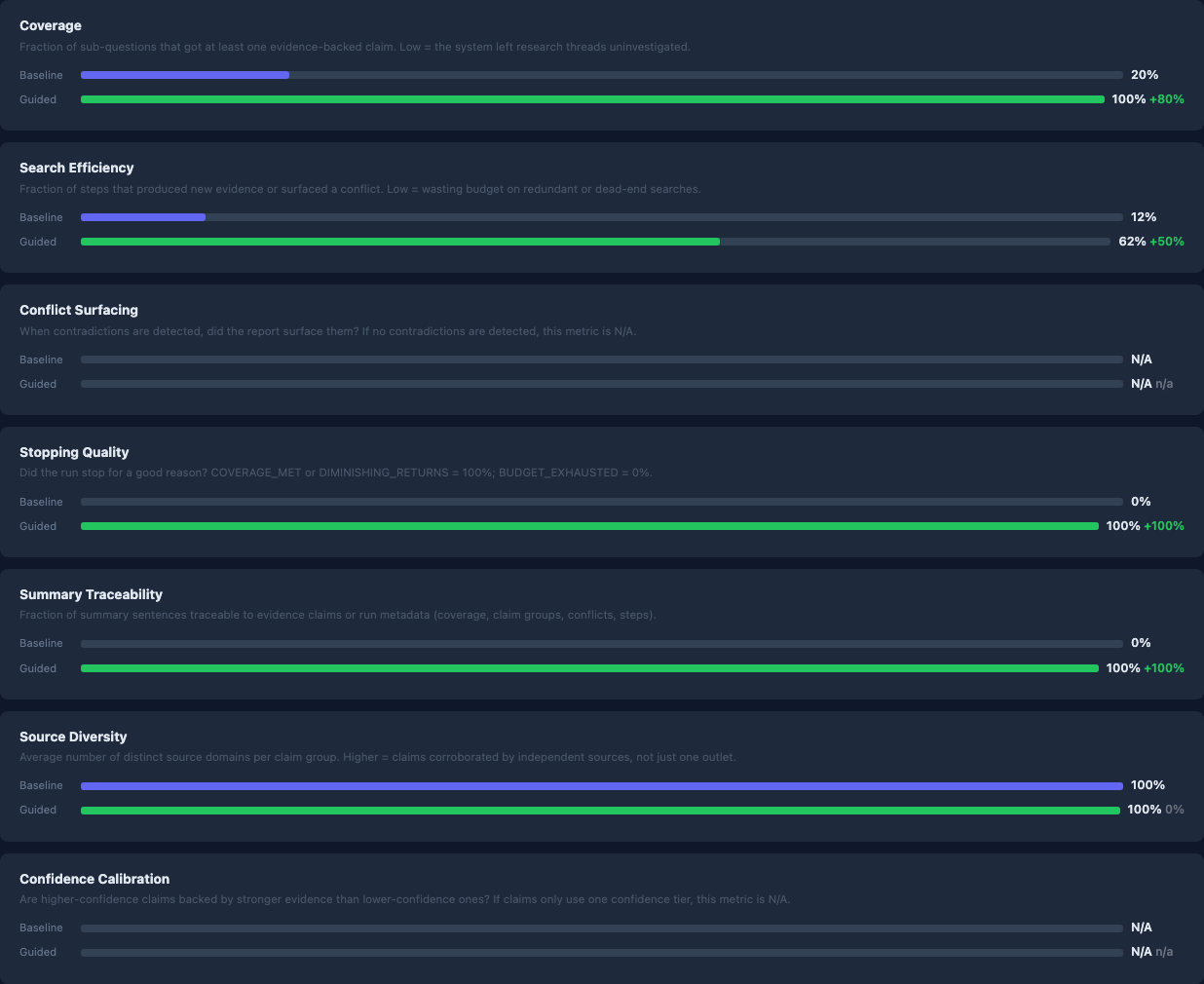
Run 2 is the result I find most interesting. Same compute envelope — 113 versus 116 LLM calls — but guided reached full coverage while baseline left two sub-questions unexplored. The gain isn’t from spending more. It’s from spending better.
The connection to PRMs and GRPO
What I built is a hand-engineered approximation of something the research community is working toward more formally.
A trained Process Reward Model does what my deterministic evaluator does — scores each step — but learns to do it from data rather than from rules. The training signal comes from (evidence state before, action, evidence state after) triples labeled by an LLM-as-judge for step quality. Once you have that, you replace the rule-based evaluator with a model call. Same interface, better generalization.
Every session already generates the training data: run_trace.json captures the full step sequence with evidence state snapshots and every LLM call with its inputs and outputs. The corpus is there. The trained scorer is what comes next.
The step beyond a trained PRM is using it to train the orchestrator itself with GRPO:
- Policy: the LLM that generates search queries and decides what to challenge
- Reward: PRM score per step + final report quality
- Group: generate K research trajectories for the same query, rank by total PRM reward
- Update: GRPO policy gradient on the higher-reward trajectories
This is Search-R1’s approach applied to evidence-driven research rather than math reasoning. The difference from outcome-only RL: you’re rewarding good intermediate steps, so the model learns when to challenge, when to stop, and which source domains are worth pursuing — not just how to write a fluent report.
What I’d build next
The honest gaps:
Trained PRM — the deterministic evaluator needs to become a learned scorer. The training data exists. The path is: LLM-as-judge labels at scale → fine-tune a small model → replace the evaluator. Same interface, better generalization.
Better conflict detection — the current conflict pipeline is preliminary. In the inference-time compute run, the conflict pipeline found zero contradictions on a query specifically designed to invite disagreement. The structure is right. The detection needs to be more aggressive.
Decomposition evaluation — the system never measures whether the initial sub-question decomposition was good. It’s the first thing that runs and the least evaluated component.
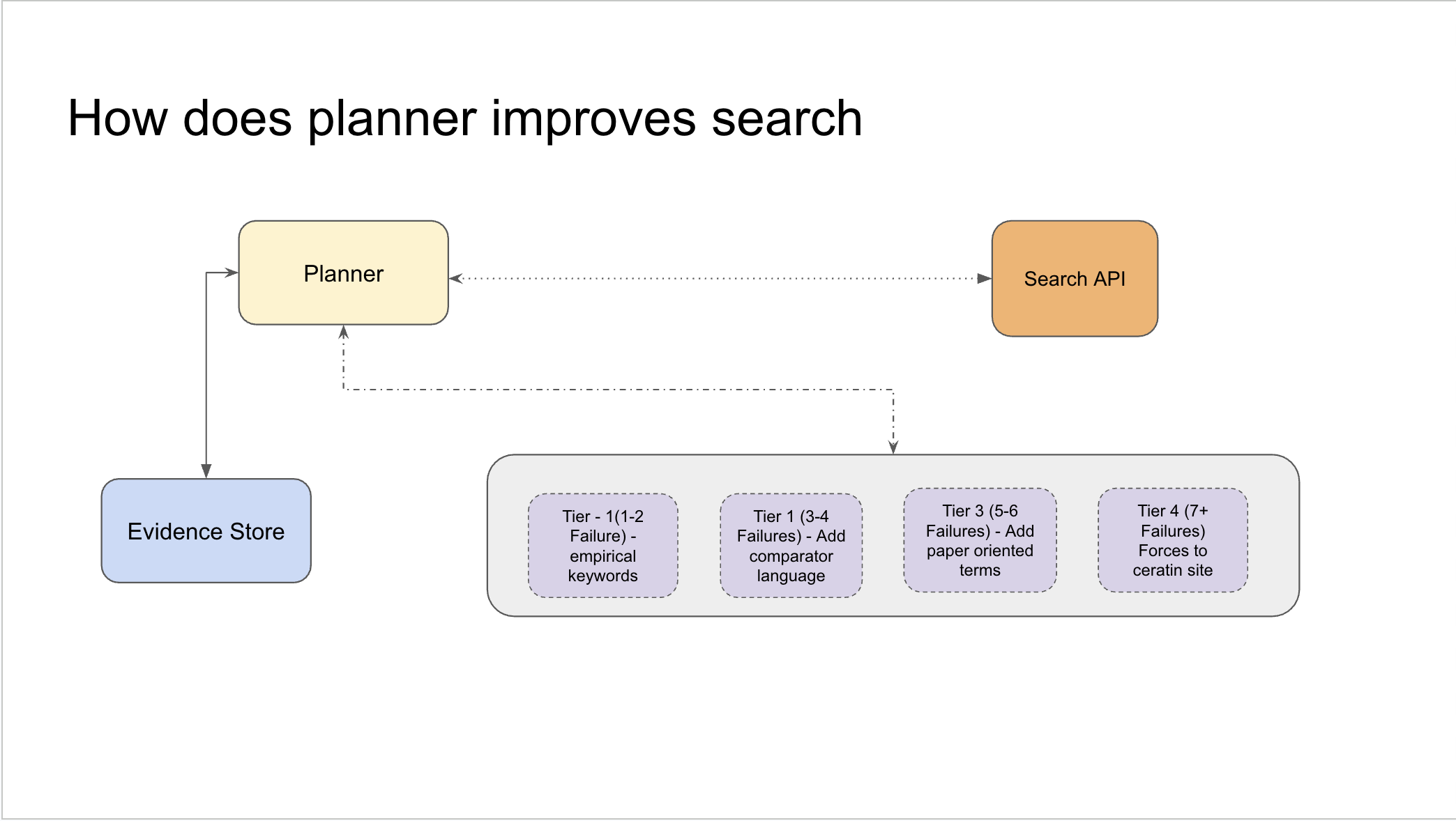
Adaptive failure recovery — when searches repeatedly fail on a sub-question, the planner escalates through hardcoded recovery tiers: simpler keywords → comparator language → paper-oriented terms → forcing a specific source domain. A learned policy would adapt these tiers based on query type and retrieval history rather than following a fixed sequence.
The takeaway
The core insight from building this: you don’t need to retrain a model to build a research agent that knows what it knows. You need the right architecture around it — an explicit evidence state, step-level signals that classify what each action contributed, and a planner that uses those signals deliberately.
The models are capable. The question is whether the structure around them is. That’s an architecture problem, and it’s one you can solve today with the compute you have.
The path from here runs through trained PRMs and GRPO-trained orchestrators — but the foundation is the design, not the scale.
Full design docs, experiment configs, and ablation results: deep-research-agent