When you build an agent, you’re not building one system. You’re building several small ML problems composed together, each one making a quality judgment, each one capable of failing silently.
I learned this while building a deep research agent. At a high level, the system takes a question, breaks it into smaller research questions, searches for sources, extracts claims, and keeps a structured record of what it has found. A planner reads that record after every search and decides whether to investigate a new question, challenge an existing claim, or stop.
I initially focused on that planner as the intelligence of the agent. What I didn’t anticipate was how much of its behavior had already been decided by the components beneath it. The planner only sees the queries that were generated, the sources that survived retrieval, the claims that were extracted, and the signal describing whether the last step was useful.
This post is about how I started identifying those sub-problems, giving each one a signal, and deciding where to spend the system’s budget. Each component has its own version of the exploitation vs exploration tradeoff, but the settings have to work together. I’ll use the research agent as the running example (post 1), but the framework applies to any agent you’re building.
Where you spend your tokens is a decision
Before getting into the sub-problems, there’s a framing that makes everything else click.
Any agent worth running in production needs to work within a finite budget. Tokens per call, API calls per run, search steps per session all have real costs. How you allocate across them is the same problem as one of the oldest challenges in reinforcement learning: exploitation vs exploration.
Exploit means spending your budget on what you already know works: query formulations that return good sources, domains that produce extractable claims, sub-questions that have already yielded evidence. Explore means spending it on uncertain paths: a new query angle, a source domain you haven’t tried, a sub-question that’s been silent so far.
Every component in your agent has this tension. The question isn’t “should I exploit or explore?” It’s: what’s the right dial setting for this component, at this stage of the run?
This is the same mindset you bring to any ML system. You don’t configure it once and ship. You instrument, measure, and revise as the system evolves. The exploit/explore settings at each component are no different from any other parameter you’d tune: initialize, run, understand the performance, adjust.
Agents are compositions of ML sub-problems
In the research agent I built, five sub-problems emerged clearly: how to formulate the search query, which sources to retrieve, how to rerank them, how to classify what came back, and what to prune or stop pursuing.
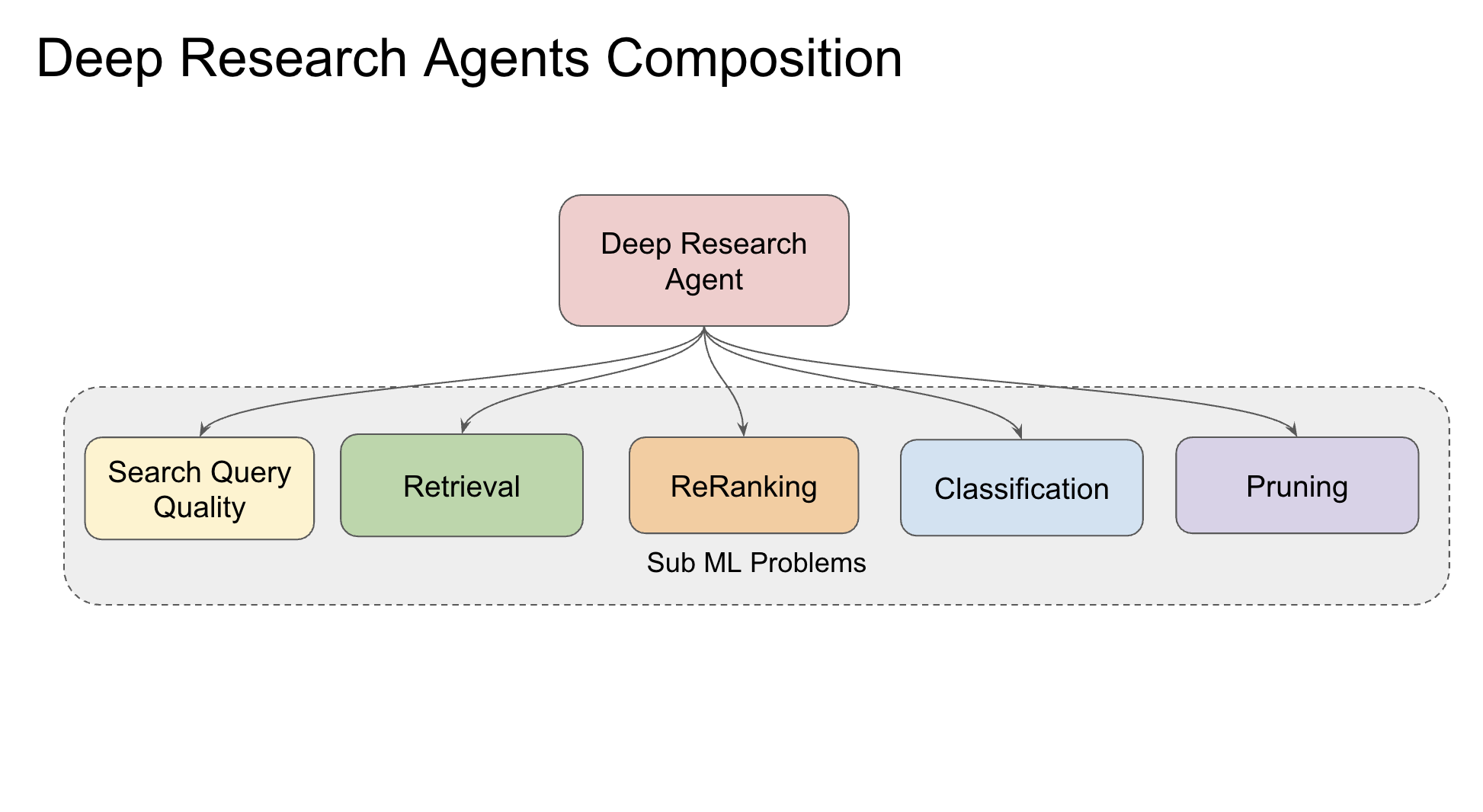 Composition of a deep research agent: five sub-problems, each with its own failure mode, each needing its own signal.
Composition of a deep research agent: five sub-problems, each with its own failure mode, each needing its own signal.
I’ll go through three of them in depth. The pattern is the same for each: identify what the component decides, define what good looks like, give it its own signal, and treat it as its own experiment. Reranking and pruning follow the same structure.
1. Search: query quality
The first decision is how to translate a research question into something a search engine can answer. A research goal and a search query are not the same thing. Bridging that gap is the actual problem.
A sub-question like When does chain-of-thought prompting fail to improve LLM performance or show minimal benefit? passed directly to a search API returns overview articles about chain-of-thought prompting. That’s not what you asked. The query needs to be reformulated: shorter, keyword-dense, targeted at the specific claim type you’re looking for.

When I added query rewriting, each sub-question produced two or three retrieval-optimized variants before searching. The agent could now try different formulations instead of assuming the first one was correct. Not because the available knowledge changed. Because the agent had more than one way to ask for it.
Query formulation is where the exploit/explore tradeoff became most visible to me. If a query returns nothing useful, there are two possibilities: the evidence is not available, or the system is asking the wrong way. Retrying the same formulation tells me very little. Trying a different formulation tests whether the failure came from the question or from the available sources.
I implemented that as a recovery ladder: empirical and benchmark terms first, then ablation and comparator language, then paper-oriented terms, and finally targeted site:arxiv.org or site:openreview.net queries. The specific levels depend on the domain. A coding agent might escalate from function-name queries to library documentation to GitHub issue search; the structure is the same either way: ordered escalation with logged outcomes. It is hand-written today, but every attempt logs what was tried and what happened.
The signal at this layer: did the query produce new evidence, repeat what I already had, or produce nothing useful? Logging that outcome for every formulation creates the beginning of a dataset for improving query generation.
→ retriever.py: query preparation, domain routing, research_mode flag
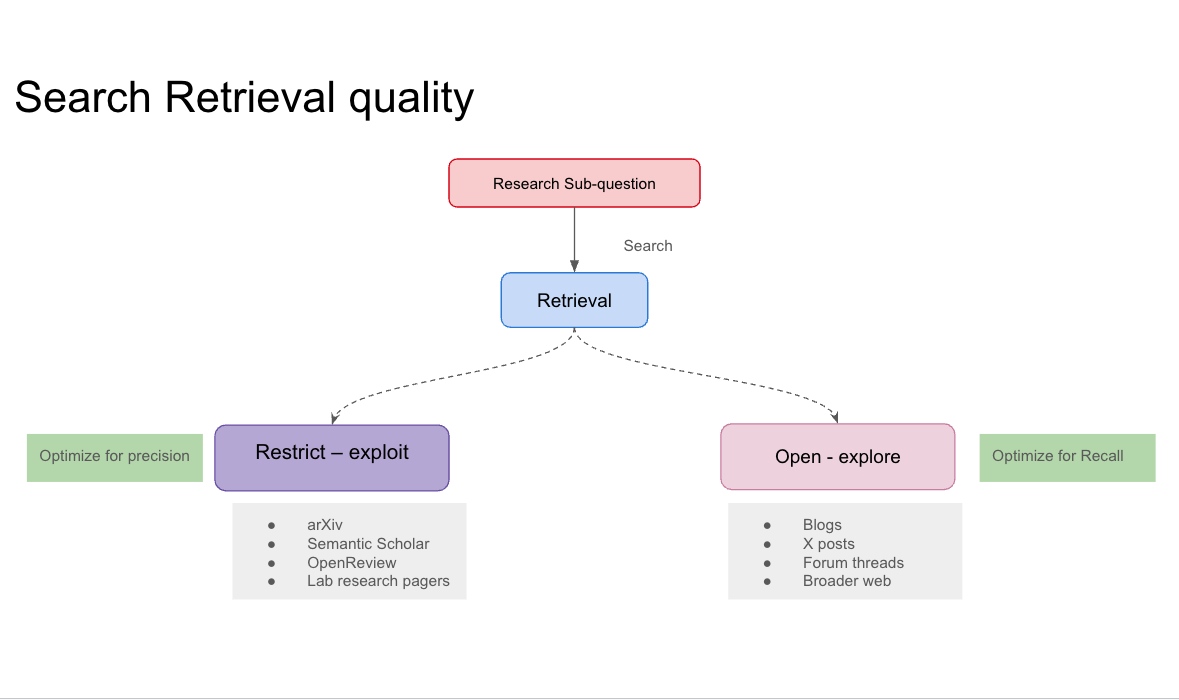
2. Retrieval: source quality
Once the query is sent, the next decision is which returned sources deserve more compute. The agent cannot read everything. Every source passed forward consumes extraction tokens, conflict checks, and storage.
Not every result that matches a query is useful. Without source filtering, retrieval returns whatever matches the keywords. Some of those have zero extractable claims. That can look like a query problem: the agent searched and produced nothing. But the query may be fine. The source selection is the issue. That distinction changes what you fix.
The exploit/explore tradeoff here is about source scope. Exploit means restricting to sources you know produce high-quality, extractable content: academic databases and lab pages in a research agent, official docs and trusted repos in a coding agent. Explore means opening to a wider pool, trading precision for recall. The right setting depends on what the sub-question is asking for: if you need verified, structured evidence, restrict hard; if you’re looking for real-world failures or practitioner experience, open up; that content rarely makes it into curated sources.
Making retrieval stricter can make the complete system worse. Tighter filtering improved precision in my build but created dead zones on hard sub-questions: the system retrieved and extracted, then rejected everything as insufficient. Retrieval cannot be optimized in isolation. Its setting affects extraction yield, coverage, planner behavior, and when the agent stops.
→ retriever.py#L126: research_mode flag: switches between include_domains (exploit) and exclude_domains (explore)
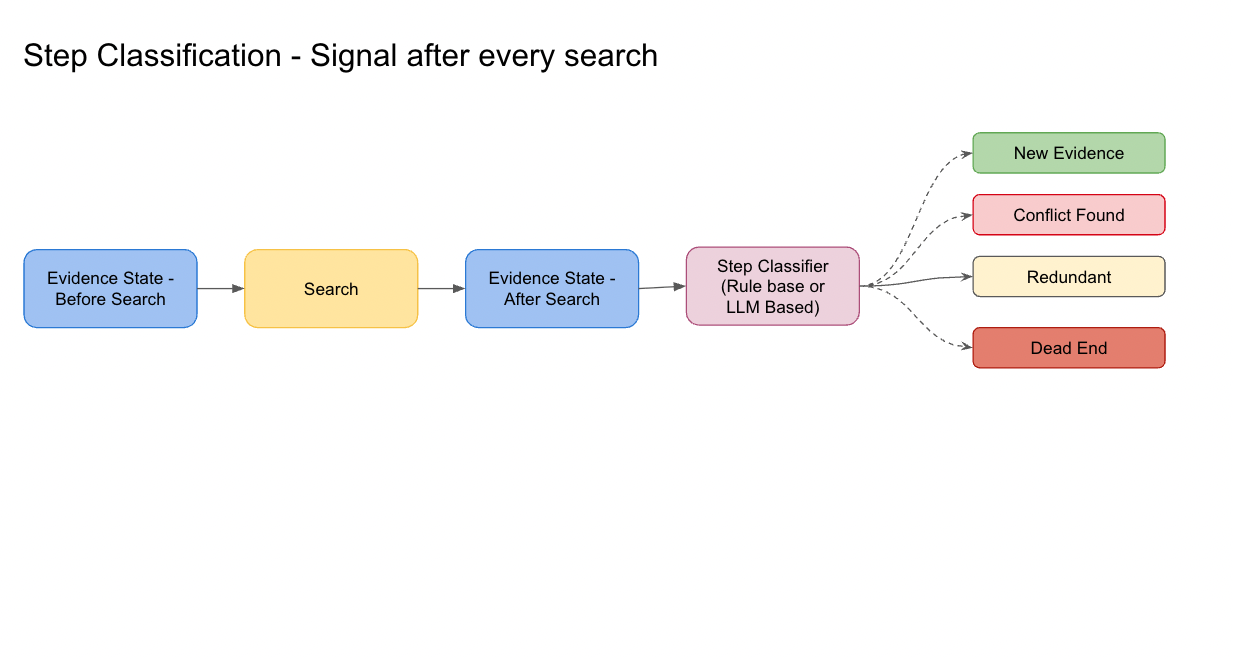
3. Step classification: did the search actually help?
After every search, the classifier compares the evidence state before and after and assigns one of four labels: new evidence, conflict found, repeated evidence, or no progress. No LLM in the loop, just state diffs.
But a classifier that only measures state changes can miss why the step mattered. A search explicitly looking for counter-evidence might return one contradicting claim and still get marked as no progress under a count-based signal. The classifier understands what changed, not what the search was trying to accomplish.
Signal quality sets the ceiling on planner behavior. A coarse signal produces a coarse planner; a precise signal misaligned with the research goal produces confident wrong decisions. The rule-based version I built is a starting point. A learned classifier could judge the full transition: what the agent knew, what it tried, what came back, and whether that moved the research forward. The harder problem is not training it. It is defining what “useful” should mean.
Optimize one at a time
During the build, I was changing query formulation, domain filtering, extraction prompts, and planner behavior at the same time. The output would improve, but I couldn’t say which change caused it. I had a better run, not a better understanding of the system.
The same problem showed up in ablation. The baseline cycled through sub-questions in a fixed order; the guided version used evidence to decide what to search next. But search API results aren’t deterministic: both versions were reading different documents even from the same query. When guided outperformed baseline, I couldn’t tell whether the planner was better or the sources were. The fix: decompose once, fetch once, pass the same documents to both modes. That made the planning policy the only variable under test.
The larger lesson: treat each sub-problem like its own experiment. Hold the surrounding system fixed, define the signal for that component, change one thing, and inspect what moved. Then put it back into the complete system and check whether the end-to-end result improved.
My working principle became: fix the signal, optimize the component, then evaluate the composition.
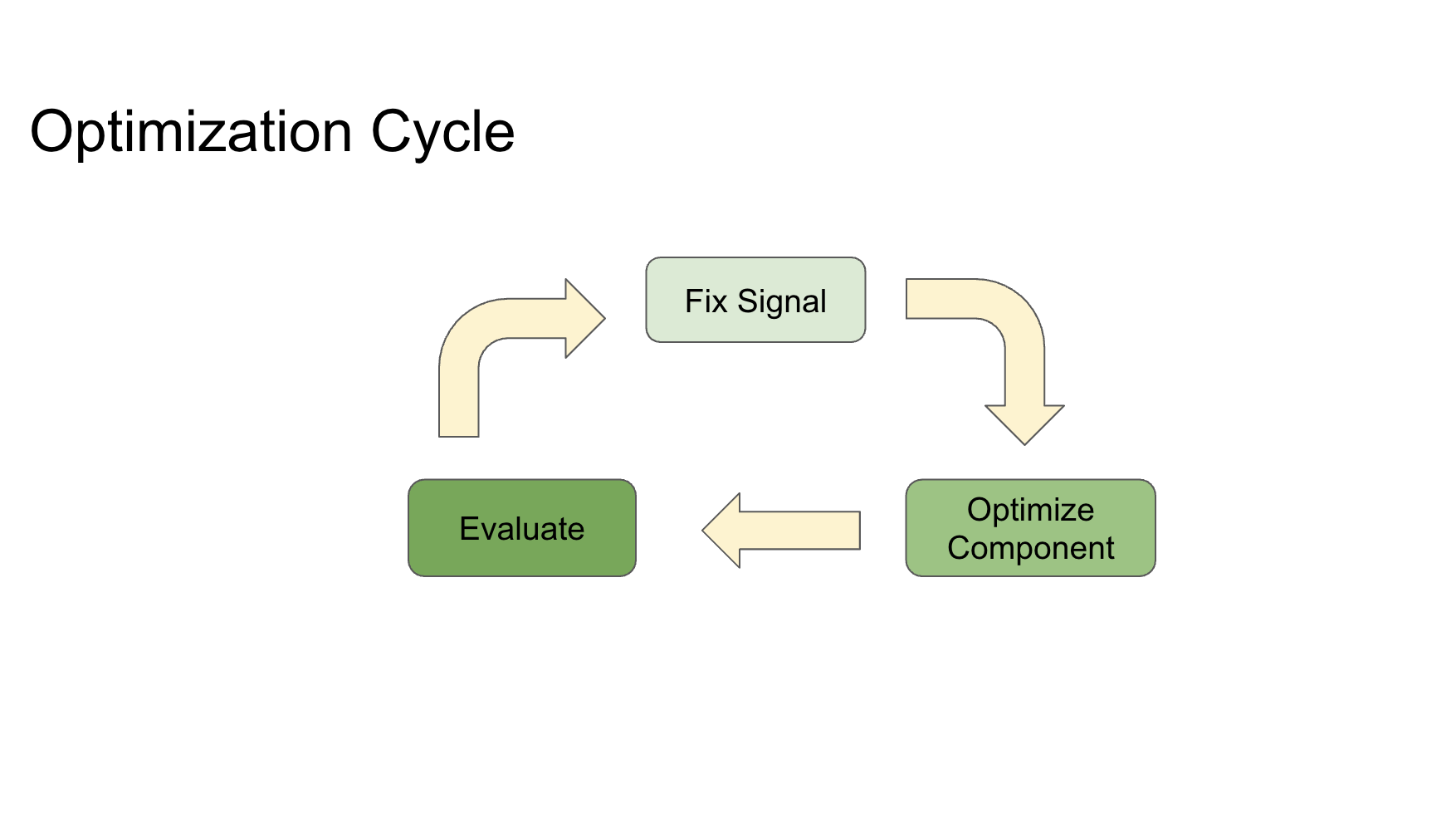
Without that separation, I could make the agent better without understanding why, and the next change could easily remove the gain.
The exploitation/exploration dial is per sub-problem
Exploit/explore isn’t a planner-level choice. It’s happening inside every component simultaneously: the query rewriter choosing between a known formulation and a new one, retrieval choosing between trusted domains and a wider pool, the planner choosing between deepening one thread and moving on.
The coordination challenge is that each layer sees different state. The planner tracks what’s still unanswered. The query and retrieval layers track what’s been tried and what came back. Without a connection between them, the planner can keep allocating budget to a sub-question the lower layers have already exhausted, not because the decision is wrong, but because the planner doesn’t have visibility into what’s been attempted below.
The fix is to surface component-level signal upward: how many times has this sub-question been tried, what strategies were attempted, did any yield anything? With that, the planner can distinguish “unanswered” from “unanswerable with the current approach” and either change the query strategy or move on. That distinction is what makes the budget go further.
Each component needs its own exploit/explore setting, but none can be optimized in isolation. The settings don’t just affect quality; they determine where the budget goes. Better planning exposes weaker retrieval. Earlier stopping leaves the writer with thinner evidence. A local improvement only counts when the complete system produces a better result.

Where this goes
Once the component-level signals are reliable, the run traces become potential training data. But the more immediate value is diagnostic clarity: when something breaks, you know which component failed and why. That’s what separates a system you can improve from one you can only restart.
The agent that looks like one system is actually several. Build accordingly.
Resources